Introduction
In my previous post, I walked through building a TensorFlow‑based playing‑card classifier that “guesses” the value of a card when presented an image of it. Once that was up and running, I realized I needed hundreds of examples—ideally generated on demand—to stress‑test the model. Here’s the story of how I tried (and ultimately abandoned) DALL·E for this purpose, and where I’m headed next.
But first, a preview of my failures:
1. Hunting for Physical Test Cards
I began by scouring my house for decks—then drove out to a local antique mall and picked up a couple of vintage sets. Unfortunately, one deck used an inset‑frame design (the pips sat in a bordered panel), and my classifier simply couldn’t recognize those. It recognized only 9 of the 53 cards, once I decided to get systematic about it.

After that, I knew I needed an automated solution.
2. “Why Not AI?” — My First DALL·E Experiments
The promise of generative image AI is that you can spin up arbitrary examples with a single prompt. I started with something like:
Create a flat, high‑resolution vector graphic of a single playing card: the 3 of Clubs.– Card shape: a portrait‑oriented rectangle (ratio ~2.5:3.5) on a solid off‑white background with a thin black border.
– Corner indices: top‑left and bottom‑right show the digit “3” in a clean sans‑serif font plus a small solid black club (♣).
The bottom‑right index and suit must be inverted (upside‑down).
– Center pips: exactly three identical solid black club symbols (♣), uniform in size (≈10% of card width).
Place them vertically at 25%, 50% and 75% of the card’s height, all upright, arranged diagonally down from left to right.
– No other symbols, textures, filigree, shadows, flourishes, or background patterns—just the card face.
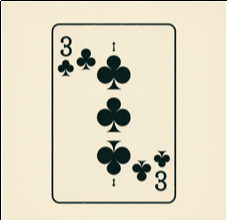
But no matter how many times I tweaked “exactly three,” DALL·E kept centralizing a giant pip (like an ace) or adding weird artifacts. I spent more than a day cummulatively bouncing between ChatGPT and Gemini for prompt improvement suggestions. They both eventually begged me to stop, and said DALL-E just wasn’t up to it. I have to agree. Just take a look at the card at the top of this post.
3. Sanitizing Prompts & AI‑Assisted Refinement
As I generalized prompts to try other cards, occasionally DALL-E would return an error and state that the prompt violated standards. After adding logging, I discovered that “queen” and possibly “joker” seemed to trigger appropriateness filters. I built a little sanitize() helper to swap out suit names for symbols, hoping to dodge policy filters and improve consistency:
// Example from my notebook
const SANITIZE_MAP = {
"spades": "♠️ suit",
"clubs": "♣️ suit",
"hearts": "♥️ suit",
"diamonds": "♦️ suit",
"joker": "wild card"
};
function sanitize(prompt) {
for (const [bad, good] of Object.entries(SANITIZE_MAP)) {
prompt = prompt.replace(new RegExp(bad, 'gi'), good);
}
return prompt;
}
Then I’d ask ChatGPT and Gemini to refine my prompt—but suggestions like “vertically align all the pips”, and other bad suggestions produced even more bizarre layouts. After a bit more back‑and‑forth, I was convinced: DALL·E just isn’t reliable for generating reasonable playing‑card geometry.
4. Pivot: A Dedicated Card‑Generator Site
Rather than force the issue, I discovered this site by Adrian Kennard (RevK®) which lets you choose suit style, pip arrangement, and several other features. The combinations are huge. These deck images can be exported as ZIP archives. My new plan:
- Download ZIP archives of several standardized card images once
- Bundle them into my test harness
- Drive my classifier through each file in CI
This way I get full control over styles and can automate coverage across all 52 cards. RevK also shared his code on github, so there is a path to adding other elements to the card generator if that’s needed. Major kudos to you, RevK!
5. Building the Automated Test Harness
Next up is a Jupyter notebook that:
- Loops through each card image in the ZIP
- Feeds it into my TensorFlow endpoint (Lambda → SageMaker)
- Logs success/failure and aggregates accuracy metrics
That’ll tell me, for example, what percentage of “standard” versus “ornate” cards my model handles correctly.
6. Looking Ahead: Benchmarking
While working on this, I started an AWS AI/ML certification path—so I plan to:
- Train Amazon’s built‑in image‑classification algorithm on my card set
- Expose it via a parallel SageMaker endpoint
- Compare its accuracy and latency side‑by‑side with my TensorFlow model
I suspect Amazon Vision will outperform me out of the box—but it’ll be a fun benchmark and a great learning exercise.
Conclusion & Next Steps
Although DALL·E couldn’t yet deliver consistent playing‑card images, this detour helped me refine my testing strategy. With a reliable ZIP‑based source and an automated harness, I’ll soon have a clear picture of my classifier’s real‑world robustness. Stay tuned for the benchmark results (and feel free to poke at the notebook yourself or challenge the classifier with your own card).
Feel free to leave comments or suggestions below—and if you’ve seen a better way to generate precise test cards, please let me know!