Introduction
I’ve been taking classes online with the goal of getting certifications in machine learning. The course “TensorFlow Developer Certificate – Image Classification” described how to put together a Convolutional Neural Network model in TensorFlow, train it on a dataset of playing cards images, and test the resulting model. The model determines which of 52 cards or joker was presented along with a confidence factor.
While getting a model working in development is instructional, I know that half (usually more than half) of the pain in software engineering is deploying the darned thing. To that end, I’ve been exploring how to build a low-latency, web-based image classifier using React, AWS Lambda, and SageMaker. I wrote a React web frontend to allow using a phone’s camera to take playing card photos within the web page. This post walks through two GitHub projects—one for the backend classifier service and one for the frontend—and shows how they fit together into a complete system.
You can give the system a try yourself at:
https://card-classifier.tarterware.com/
Project Overviews
1. Playing Card Classifier (Backend)
Repo: https://github.com/SteveTarter/playing-card-classifier
-
Tech stack: Python, TensorFlow (Keras), AWS SageMaker
-
Model: A Sequential Convolution Neural Network trained to recognize 53 outputs (52 cards + joker)
-
Deployment:
-
Model artifact saved to S3
-
SageMaker endpoint for real-time inference
-
Lambda for interrogating the SageMaker endpoint, then saving and reporting results
- Result save to S3 bucket to allow retraining on new card samples.
-
2. Playing Card Classifier Frontend
Repo: https://github.com/SteveTarter/playing-card-classifier-frontend
-
Tech stack: React, HTML5 Canvas, CSS
-
Features:
-
Capture images via file upload or camera stream
-
Zoom, crop, and normalize aspect ratio to 224×224 pixels
-
Display selected card image.
- After classification, display card name and per cent confidence.
-
-
Hosting:
-
Static site on S3 + CloudFront (HTTPS + CORS configured)
-
Calls API Gateway → Lambda → SageMaker
-
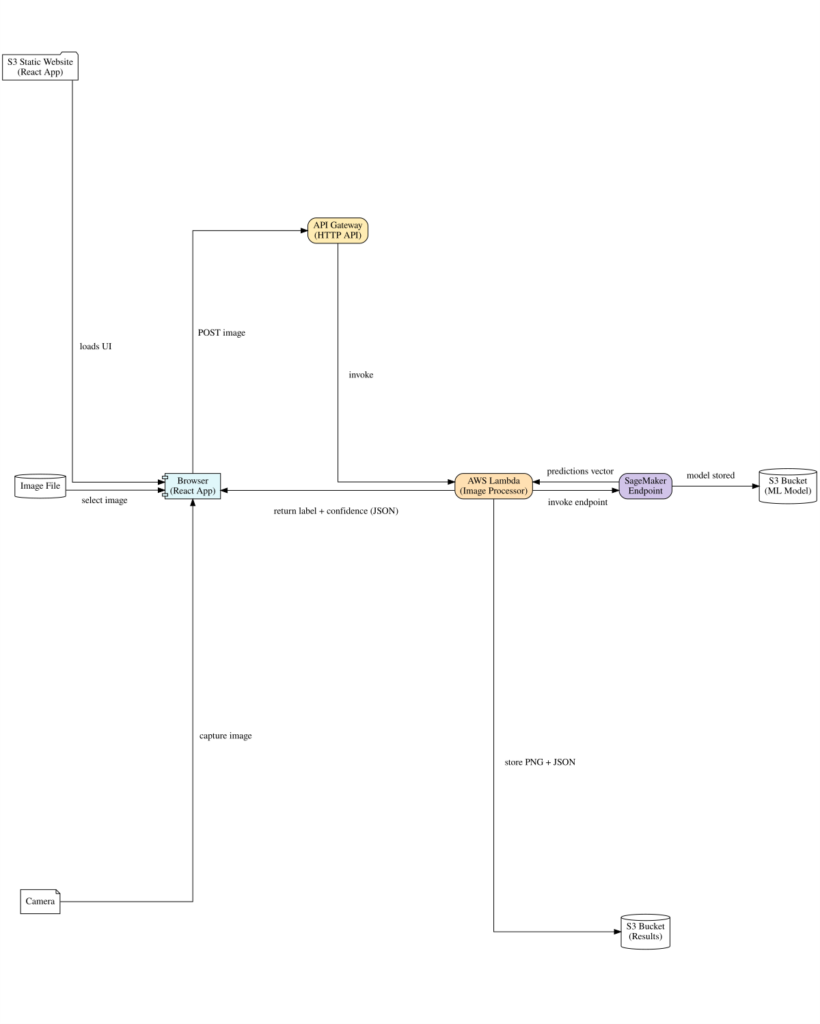
System Architecture
Below is a high-level diagram showing how the pieces interact:
How It Works
-
Image Capture & Preprocessing
The React frontend grabs an image from the user’s camera or file picker, crops/zooms it to maintain card aspect ratio, and resizes to 224×224 pixels on an HTML canvas. -
API Request
The preprocessed image is base64-encoded and sent via an HTTP POST to API Gateway. -
Serverless Inference
API Gateway triggers a Lambda function that:-
Decodes the image
-
Calls the SageMaker endpoint with the Tensor input
-
Receives a probability vector for each card label.
-
-
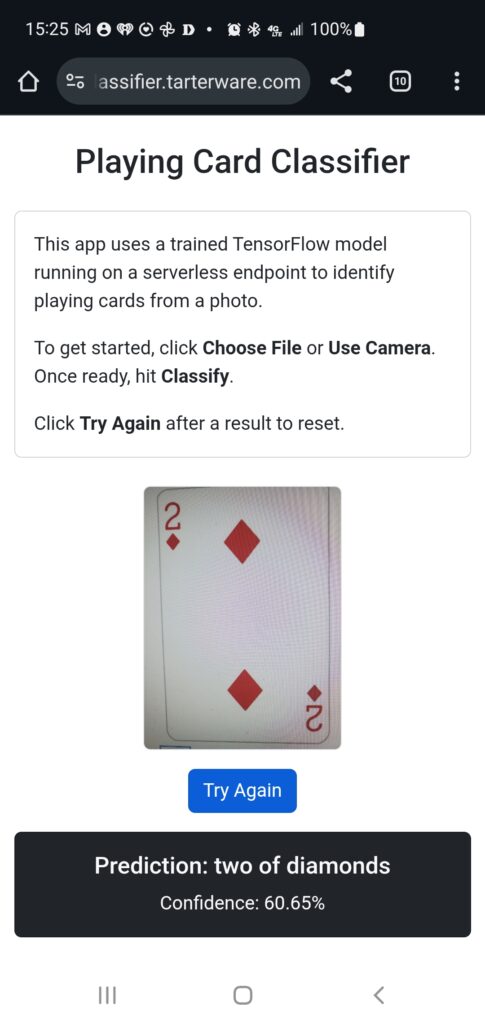
Results Display
Lambda returns the label of the highest probability card and the probability value; the frontend displays them under the original image.
Screenshot
Wrap-up
Combining a React frontend with AWS serverless inference provides a flexible, scalable way to run computer vision workloads in the cloud. Check out the two repos and let me know what you think!